
5.1 经典的语义相似度计算方法
许多经典的相似度计算方法常用于信息检索和自然语言处理研究中,比如Mutual information、Dice’s index、Cosine function、Jaccard’s index、Overlap和equivalence index等[5]。假设A和B分别为一个文献检索系统的子集,Ω表示全集,它们的定义分别为:

●Dice’s index:
![]()
●Cosine function:
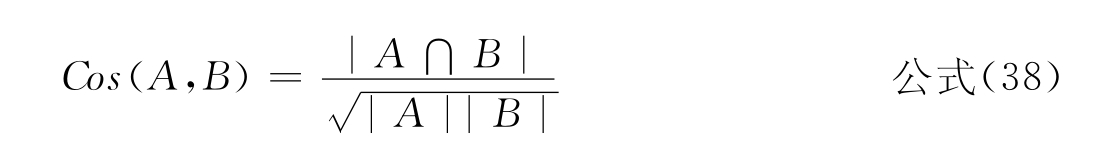
●The measure N:
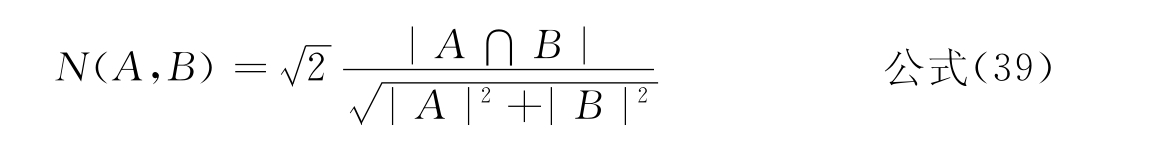
●Overlap measures O1和O2:
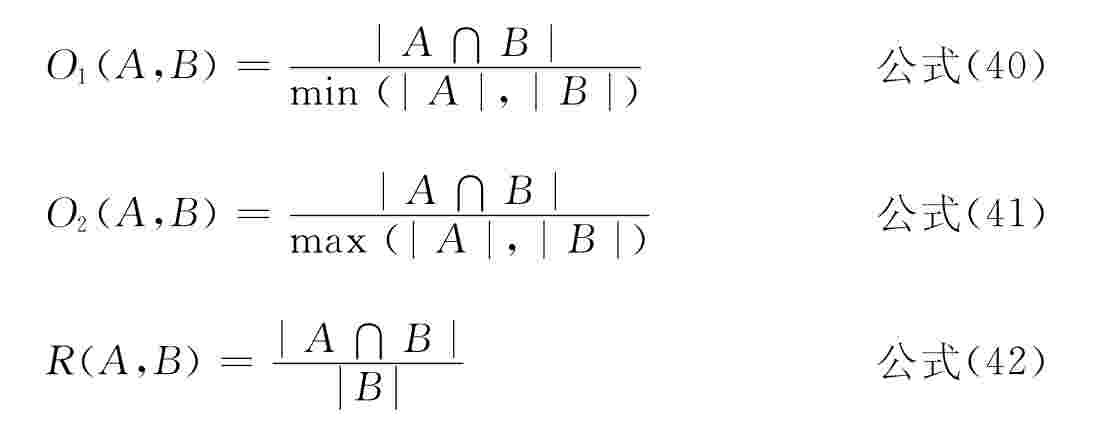
●Recall R和Precision P:
![]()
上述公式可以统一表示为:
![]()
检索语言的兼容转换是有方向的(directional),或者说是不对称的(asymmetry)。由语言A向语言B转换并不等同于从语言B向语言A转换。因此,大部分上述相似度度量方法并不适应用于检索语言的概念兼容转换。主要原因在于:
●大部分现有相似度度量方法都是对称的。
●如果概念在文献数据库中出现的频率很低,那么概念之间的语义关系不能被准确地识别出来。
●它们只能度量概念之间的相似程度,而不能定义概念之间
具体的语义关系。
IM和LogL等方法并不能体现检索语言兼容转换的方向性。粗糙集是一种较为新颖的处理模糊性和不确定性的数学工具,已经被成功应用于语音识别、信息检索和图像处理等领域。结合粗糙集和检索语言的一些基本理论,建立基于粗糙集理论的检索语言兼容转换模型和算法,从而根据概念的出现频率等特征鉴别出正确的概念语义关系。
上一篇:财政赤字的经济影响
下一篇:畲族彩带图文样式寓意




.jpg)
.jpg)
